On crypto / web3 / web5 / watchamacallit
“The wonderful thing about standards is that there are so many of them to choose from.” —Grace Hopper
Idealogical dogfights are not a new phenomenon in tech. Emacs vs Vim, Linux vs Windows, Java vs C++, OSI vs TCP/IP, MP3 vs OGG, Mac vs IBM-PC, AOL vs the open internet, HTML5-based mobile apps vs native apps, desktop vs mobile. The list goes on and on. We just haven’t had one in a very long while … until now.
Yes, I’m talking about the web2 <> web3 one. Who knows what those labels even mean. The debate jumps around from decentralization to blockchains as a poor database to the financialization of everything to security mishaps to the influx of venture capital to UX concerns to over-priced monkey jpegs to non-government currency to securities law and regulatory compliance to…
The naming (crypto, web3, and even a web5 now!) has been rather unfortunate, in my opinion: ‘crypto’ confuses with cryptography and cryptocurrencies (which are only one application of this tech), while ‘web3’ counter-positions directly against ‘web 2.0’ which triggers the wrong arguments (”how is web2 bad” rather than “how might web3 be useful”).
For purposes of sanity, I will circumvent any ideological debates in this post — things like merits of decentralization for decentralization’s sake or government oversight on the currency of a land. I will also not make a stance on whether web3 is “the future” — this post claims no predictive power and simply consider it as any new thing: it may work, it may not.
Fair warning: I will be quoting heavily from the writings of others that have informed my understanding of the space.
This is a long post, so let me just lay out the contents upfront so you know what to expect:
- How technological revolutions behave
- Carlota Perez’s famous theory, going back 200 years
- Other very smart people sharing examples of early technology and its evolution
- My own experiences seeing Mobile emerge, disrupt and mature
- Financial skullduggery
- My view of the crypto / web3 space
- First principles: what lies at the core
- An analogy with AWS to help extrapolate
- New primitives
- A round-up of new functionality made possible by web3 (agnostic of its application)
The inevitable march of technology
The phrase “inevitable march” sounds grand, conjuring up images of an 18th century cavalry decked in all their finery and parading through town as a show of strength before they set out to battle. It couldn’t be farther from the reality of a technological march — technologies start in poorly-lit basements, eating ramen for lunch and dinner, wearing the same unwashed jeans and dank grey hoodies for days, monochrome and cryptic text its only regalia. From there they make their ascent, slowly.
Carlota Perez has written the seminal work in understanding the business of technology. She studied 200 years and four major technological revolutions to apply the lessons to a fifth one:
- The Industrial Revolution, which began in 1771 in Britain
- The Age of Steam and Railways, which began in 1829 in Britain
- The Age of Steel , Electricity and Heavy Engineering, which began in 1875 in the United States
- The Age of Oil, Automobiles and Mass Production, which began in the United States in 1908
- The Age of Information and Telecommunications, which began in the United States in 1971
Fred Wilson explains her framework on his blog, where he says:
What she found was that there are two phases of every technological revolution, the installation phase when the technology comes into the market and the infrastructure is built (rails for the railroads, assembly lines for the cars, server and network infrastructure for the internet) and the deployment phase when the technology is broadly adopted by society (the development of the western part of the US in the railroad era, the creation of suburbs, shopping malls, and fast food in the auto era, and the adoption of iPhones, Facebook, and ride-sharing in the internet/mobile era).
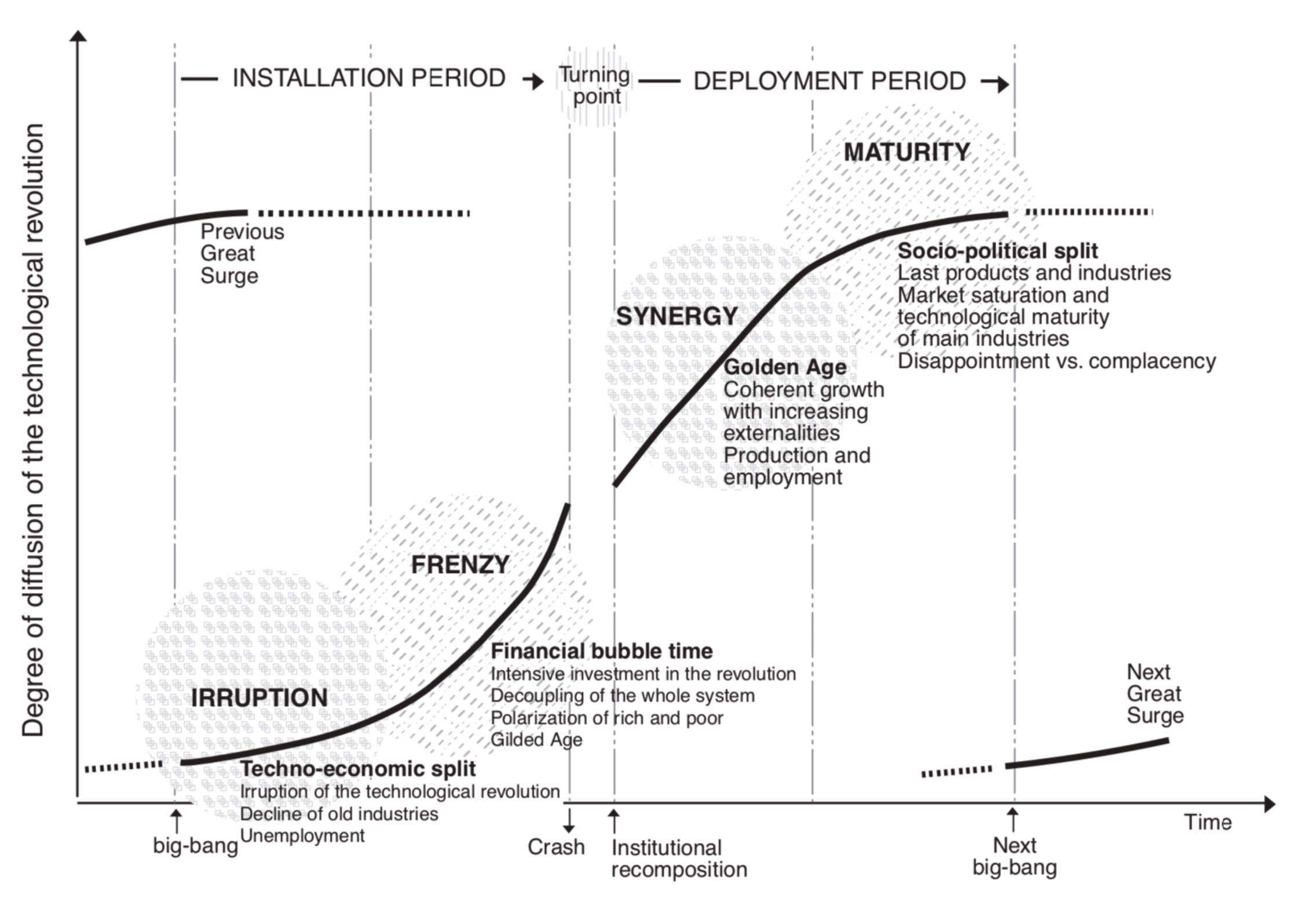
Web3 is still in the early parts of the Installation phase. Perez describes that and contrasts between ‘Irruption’ and ‘Frenzy’ in her book (emphasis mine):
The first half can be termed the installation period. It is the time when the new technologies irrupt in a maturing economy and advance like a bulldozer disrupting the established fabric and articulating new industrial networks, setting up new infrastructures and spreading new and superior ways of doing things. At the beginning of that period, the revolution is a small fact and a big promise; at the end, the new paradigm is a significant force, having overcome the resistance of the old paradigm and being ready to serve as propeller of widespread growth.
When technologies show small facts and a big promise, they get a target on their backs. It is easy to dispute their worthiness — “show me a single example of utility or success story”. Pitting facts against promises is not a useful debate as the two sides end up talking past each other rather than debating either aspect separately. A lot is at stake, so these debates are heated. Perez writes (emphasis mine):
The process of installation of each new techno-economic paradigm in society begins with a battle against the power of the old, which is ingrained in the established production structure and embedded in the socio-cultural environment and in the institutional framework. Only when that battle has been practically won can the paradigm really diffuse across the whole economy of the core nations and later across the world…
It is even easier to dismiss new technologies, because they do not start off looking revolutionary. When Stratechery covered Airbnb’s Categories feature in their recent mega release that the Airbnb CEO called “The biggest change in a decade”, Ben Thompson wrote (emphasis mine):
A point that I regularly make in the context of new technologies is that the v1 is often disappointing because it simply apes what came before; it’s the v2 that is transformational because it does something that was not possible previously.
My go-to example here is digital advertising. For years we heard about how print dollars were turning into digital pennies, and if you consider the format of early digital advertising, it made sense: print advertisements were laid out next to the content, so it’s not a surprise that the v1 of digital advertising was laid out next to the content. And, unsurprisingly, given it was in a worse format — relatively low resolution screens where the ad usually scrolled out of view — these ads monetized poorly.
What transformed display advertising was the feed: now ads could be dynamically loaded and take over the screen even as they felt less intrusive and more native; moreover, the work necessary to customize the feed was broadly applicable to the work necessary to customize the ads. These ads monetized dramatically better than not just the v1 of digital ads, but than print ads — print dollars and digital dimes became print pennies and digital $10 bills.
The critical distinction between v2 and v1 is that while v1 was an imitation of what came before, v2 was something that was only possible with digital, which brings me to Airbnb Categories.
Another booking site, like, say, Booking.com, could technically do categories; a website isn’t a physical object like a newspaper. What, though, would the categories be, given that most of the inventory on Booking comes from hotels? After all, one of the raison d’êtres of hotels — the reason I always choose them when I am traveling by myself for business — is their consistency. Sure, there are different features — number and size of beds, whether or not there is room service, etc. — but all of these features are a secondary consideration after location. That’s why location and date are how you search for hotels on Booking.com, or any other lodging website, including Airbnb — at least until now.
What makes Categories so compelling is that it provides an organizing principle for users that is completely new: instead of starting with location or even dates you start with the type of experience you want, and filter down from there. This is very compelling from the end user experience, as it is an entirely new vector on which to generate demand; it’s just as compelling from the host perspective, as it provides a means to drive demand for and towards experiences that most users would never even encounter, simply because they would have never thought to search the location in which they are found. To put it another way, this is something that only Airbnb could do, and it is something that deepens the company’s competitive advantage.
The common argument that a new technology don’t seem to enable anything new is often made against web3. Thompson’s examples above show how technologies start by creating skeuomorphic replicas before finding their own footing and truly innovating. The skeuomorphic replicas — doing the old thing in a new way without any apparent incremental value — are a necessary stepping stone.
Not only do applications of new technologies seem like replicas without new value, but they may even be a step back. Albert Wenger, managing partner at Union Square Ventures, writes about Clayton Christensen’s disruption theory (emphasis mine):
This requires telling a bit of a story and also understanding the nature of disruptive innovation. The late Clayton Christensen characterized this type of innovation as being worse at everything except for one dimension, but where that dimension really winds up mattering a lot (and then over time everything else gets better also as the innovation is widely adopted).
The canonical example here is the personal computer (PC). The first PCs were worse computers than every existing machine. They had less memory, less storage, slower CPUs, less software, couldn’t multitask, etc. But they were better at one dimension: they were cheap. And for those people who didn’t have a computer at all that mattered a great deal. It is exactly this odd combination that made existing computer manufacturers (making mainframes down to mini computers) ignore the PC. They only focused on all the bad parts and ignored the one positive dimension or to the extent that they understood it they tried to compete by making their own product cheaper. Other than IBM, they never embraced the PC and went out of business or were absorbed by other companies.
I recently tweeted some examples of new technologies that were derided for being worse, pointless, unnecessary complex when they first came out:
Trying to create a thread of tech that was new at the time and dismissed, that I remember from my own direct experience growing up (or old, more recently) in the last ~two decades.
— Umang Jaipuria (@umang) June 7, 2022
If you remember similar stuff, reply below 👇
Even as recently as the early 2010s, in the shift to mobile platforms, there were fiery arguments decrying mobile. The ones that I found myself in the middle of went thusly:
-
Ad tech was said to be near its end as it was impossible to show banner ads on tiny mobile screens. Either mobile usage would never be monetizable or would have to resort to charging users for what previously was free on the desktop (ad-supported).
-
Another argument made against ad tech with the rise of mobile, and against the mobile platform itself, was that smartphones were only meant for frivolous usage. All serious activity (like purchases) happened on the desktop. It was impossible to understand the relationship between mobile browsing and corresponding purchases on the desktop because it was impossible to connect device IDs and cookie IDs in the desktop browser. This was taken as a hard limitation on ad spend on mobile — it would never be a valuable ecosystem.
-
Building mobile apps was considered futile because your browser was the ultimate app store — everything was already available and immediately installed upon page load (by typing or clicking on a URL!)
-
It was considered impossible to create sophisticated experiences in mobile apps because once installed, they would rarely be updated by users. It was also impossible to run a/b tests inside apps (this was a real limitation for a short while as the infrastructure had not been built yet).
The list goes on. Yet here we are: mobile has become the default computing platform for end-users.
What was happening then was the classic Irruption phase as laid out by Perez: firstly, skeuomorphic replicas were getting built as smartphone apps and, secondly, these apps were getting built in parallel with the infrastructure developing, and hence lacked much of the sophisticated capability we take for granted today.
“They laughed at Columbus and they laughed at the Wright brothers. But they also laughed at Bozo the Clown.” —Carl Sagan
However, these analogies can lead to fallacious arguments. Simply because successful revolutions sucked when they were in their infancy does not imply that a new technology that sucks today is guaranteed to become revolutionary. Benedict Evans hits the nail on the head:
It is important to recognize that early failures and lack of utility also do not have predictive power.
While I’ve focussed almost entirely on applications of technology thus far, I would be remiss in not making a point about the financial skullduggery that abounds in crypto. The first century or so of equity markets — arguably the greatest invention of capitalism — looked like this (source):
For those that view crypto and digital assets as nothing but a lawless cesspool of frauds and scams, it is worth remembering that equity markets were no different in the 19th century and early 20th century. The 1800s endured a full century of rampant fraud and market manipulation before finally getting its act together in post-1929 crash.
My lens on Web3
I see crypto / web3 / blockchains as a large, open developer platform that allows you do a few specific things that were impossible before. It reminds me of when the LAMP stack took off: any one could create a database-backed web app that was more than a static website. Practical applications came later.
At its core, web3 is simply a piece of open source code that is immutable and runs transparently. While much of the world’s software is based off open source software, it can be changed by the companies running that software and from the outside you cannot tell what exactly is being executed. In contrast, smart contracts cannot be changed and you can always look at the code to know what exactly is being executed as they are executed by a neutral third parties (the blockchain validators).
It is possible to draw parallels from AWS: the fundamental primitive of AWS was to convert physical computer servers into virtual machines that you could “rent”, “turn on”, “turn off“ purely through software. Once they had that, everything else AWS built was giant developer platform with different services and tools built on that virtual machine. The services ranged from storage services of different kinds (object storage, file systems, caches, etc) to compute services of different kinds (vanilla servers, containers, batch processing, serverless, etc) to network management to specialized computation like training machine learning models or encoding / decoding video: there are 226 services on their product page! But the underlying primitive is simply that of a virtual computer that can be created and managed over the internet.
Web3 is a similar virtual computer owned by nobody that enables specific services to exist. There is likely going to be similar explosion of services and tools for developers that get built on these new primitives that web3 enables, and an even larger explosion of apps built on top of those developer tools.
So what are the primitives that smart contracts enable?
New Primitives
Tyler Cowen and Alex Tabarrok, writers, public intellectuals and professors at the economics department at George Mason University, wrote a chapter on the fundamentals of the technology and said this about new functionality (all emphasis mine):
Property rights for digital assets
An NFT is just a cryptographic hash of an artwork (or other digital file) signed with a digital signature.
Is it strange to buy a digital signature? Maybe. But people buy autographs all the time. In 2021, a rookie card signed by NFL quarterback Tom Brady sold for $3.1 million. One collector said, “For me, an autograph on a card makes that card both unique and special. The autograph means that the signer came in contact with the card; therefore, owning a signed card provides a direct, physical link to its signer. That link makes the card special and forever distinguishes it from all of its unsigned cousins.”
You can also see that NFTs can serve as a system of property rights for internet goods.
If you think that virtual reality or the internet more generally is going to be even more important in the future, plausibly its property rights will be a lot more important, too. So with NFTs we have invented a whole new type of property right. And property rights are a key economic concept, as we have explained throughout this textbook. One reason that we, Tyler and Alex, are interested in NFTs is because we are intrigued that humans have invented a new kind of artwork and a new kind of property right at the same time. Almost nobody was expecting this even 15 years ago.
Automated market makers
Order books can be run on blockchains but for a variety of reasons decentralized finance has pursued an innovative and surprising alternative method of trading securities. On a decentralized exchange like Uniswap or Curve, traders trade not with each other but with a smart contract known as an Automated Market Maker (AMM).
Using AMMs to trade securities is very new and strange but it does have several advantages. Order books require thick markets which is one reason why the NYSE is only open from 9:30 am to 4 pm daily and not on weekends or holidays. By restricting its hours, the NYSE concentrates traders making the market thicker. In contrast, since AMMs are run by smart contracts they can be available 24 hours a day, 365 days a year, and from anywhere in the world.
Another big advantage of AMMs and smart contracts (SC) is that they are “composable”—meaning one SC can call another SC.
Composability makes it possible to create sophisticated financial contracts by putting together smart contracts like Lego blocks. More generally, since code uploaded to a blockchain doesn’t go away each new smart contract added to the system adds to the potential capabilities of every other smart contract.
Flash loans
Borrowing and lending without any paperwork or identification is remarkable, but how about borrowing millions without any collateral? As we mentioned earlier, this is also possible in the DeFi world but you must borrow and lend quickly. Flash loans are loans that are made and repaid in one combined transaction so that if the loan can’t be repaid then it is never made. Flash loans are an entirely new financial innovation.
DeFi for the developing world
Traditional finance relies on legal documents like contracts, titles, and personal identification and thus it ultimately relies on a legal system that can enforce those contracts quickly, reliably, and at low cost. Relatively few countries in the world have all the required abilities, which is why traditional finance clusters in a handful of places like New York, London, Singapore, and Zurich.
Decentralized finance, in contrast, relies on smart contracts and cryptographic identification that work exactly the same way everywhere. Decentralized finance, therefore, could be broader based and more open than traditional finance. Indeed, decentralized finance could prosper in precisely those regions of the world that do not have reliable legal systems or governments with the power to regulate heavily.
A permission-less database
Albert Wenger, in his post titled “Why Bother?”, shares his view on the fundamental abstraction enabled by the blockchain:
A blockchain is a worse database. It is slower, requires way more storage and compute, doesn’t have customer support, etc. And yet it has one dimension along which it is radically different. No single entity or small group of entities controls it – something people try to convey, albeit poorly, by saying it is “decentralized.”
Now the important part to keep in mind here is that prior to the Bitcoin Paper we literally didn’t know how to have permissionless. Yes, we had distributed databases. And yes, we had federated databases. But all of those still had a small group of entities in charge (cf pretty much every financial network such as ACH or VISA). We didn’t have a protocol for maintaining consensus – meaning agreeing on what’s in the database – that would allow anyone to join the protocol (as well as anyone to leave).
It is difficult to overstate how big an innovation this is. We went from not being able to do something at all to having a first working version. Again to be clear, I am not saying this will solve all problems. Of course it won’t. And it will even create new problems of its own. Still, permissionless data was a crucial missing piece – its absence resulted in a vast power concentration.
Where to from here?
We are debating the wrong things. It is not useful to point at scams or the lack of clear real-world utility so far. We should be discussing real use cases, solutions to problems, and lessons from experiments.
The best thing to do when something new comes along is to poke it, prod it, see if it moves, pour some liquid on it, heat it, cool it, see what happens. Develop hypotheses and test those hypotheses. Experiment and expand our knowledge of what works and what doesn’t.
(I’m still learning about the space so if you have feedback on any of this, I’d love to hear)