Deterministic vs Non-deterministic products
It used to be that you could ask your customer simple questions: How do you do this today? What happens next? What is a successful outcome? What is not? What makes your work hard? What might make it easy? The answers would provide a straightforward path to determining what your product should do to solve their problems. With the answers, you would write a product specification: a detailed list of instructions for how the software must behave, according to a set of inputs from the user: clicks, taps, typed text. Sometimes different customers (or use cases) demanded different behavior and you would create branches in the logic accordingly.
Products behaved exactly according to this set of written rules — the “business logic”. Any deviation from these rules was a bug to be squashed. It was all very deterministic.
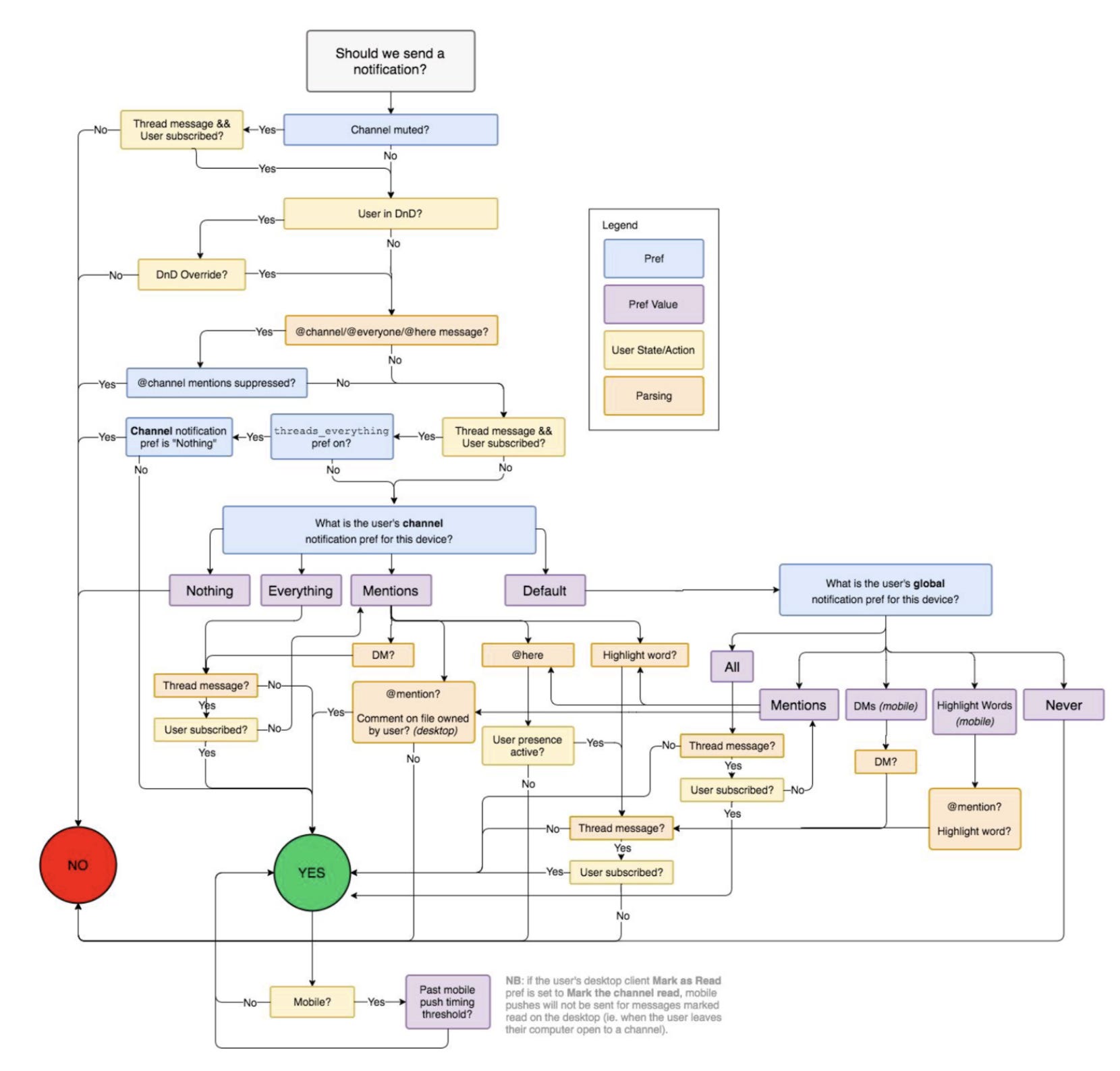
You’ve probably seen this flowchart of how Slack decides when to send a push notification — it does the rounds on Twitter / LinkedIn every few months. It is the perfect example for a deterministic flow: all the cases are known in advance, and minutely accounted for. (Later in this post, we will take a look at making this non-deterministic.)
These days products are more complex:
-
If a product has a machine learning feature, as is increasingly frequent, its behavior is by definition probabilistic. It is impossible to be prescriptive or even know in advance what the model will churn out. With sophisticated techniques like deep learning, it is also impossible to retroactively understand why the model behaved a certain way.
-
Internet products often contain user generated content (like social feeds, customer reviews, etc) or depend on externalities you cannot control (like Uber drivers or Doordash restaurants). You can never fully know all the inputs to your product and hence the resulting user experience.
To make things more convoluted, we don’t like dealing with uncertainty. Our minds are tuned to interpreting the world by looking for reliable, repeating patterns. Users’ expectations of products is from this frame of reference — if nothing obvious has changed in how they use it, they expect nothing to change in how it behaves. Deterministic.
There is an ever-widening gap between that expectation (deterministic) and how products are now designed to act (non-deterministic). The tweet below is a perfect example of this dissonance.
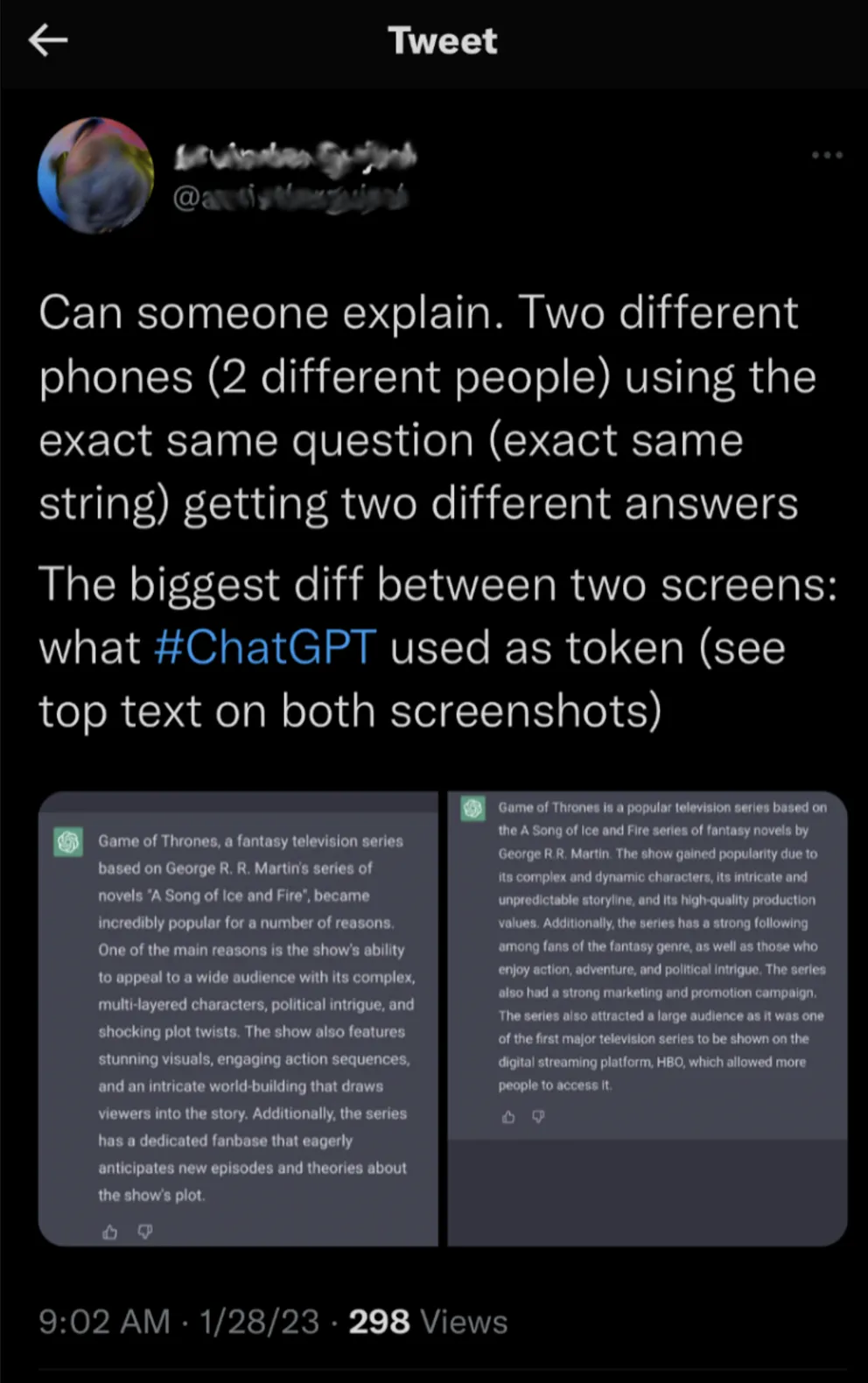
In a world where artificial intelligence is about to “eat software” (c.f. Software is eating the world), how do you think about building non-deterministic products? What do you do when you cannot simply write “product requirements”? How do you minimize the dissonance for your users?
Here are 5 mindset shifts to make when building such products:
1. Think in terms of objectives
Imagine a self-driving car: you can neither steer it nor step on the gas or brakes, but you can give it a destination. The “destination” for these products is the outcome you want to achieve. Minutely specifying product behavior is replaced by defining product objectives and the stepping stones to that outcome. These typically take on the form of success metrics (leading and lagging) that can become the objective functions of the underlying models. This does mean you need to build and instrument your product where the intermediate and final success states are legible to the engines driving the product.
2. Create feedback loops
You cannot be prescriptive about what to do in every situation, but you can tell a model when it gets things wrong and when it gets things right. Create affordances in the product for users to express this, as they use the product. Models take this feedback into their training and constantly update themselves — your product is constantly improving on its own.
Here is Sarah Tavel on feedback loops:
When I was at Pinterest leading product for the Discovery team, we started to leverage deep learning for our recommendations. It was always the case that while deep learning enabled a step-function change in the results (as measured by user engagement), the results got dramatically better once we took that user engagement data and fed it back into the model to further tune the results. We’d go from a place of discontinuous change with each step-function upgrade of the model, to a world with a compounding feedback loop.
Even Chat GPT has a simple feedback mechanism — notice the thumbs up / thumbs down in their UI? One of the slickest feedback mechanism is in TikTok, where swiping away a video before finishing is negative feedback and watching it in its entirety is positive feedback — users generate a feedback loop in the natural course of using TikTok, without taking any extra steps.
3. See like a state
The book Seeing Like a State is a treatise on how governments have evolved to understand a nation, its citizens, and their lives from a central perspective to aid their planning — things like permanent last names, standardization of weights and measures, land surveys, all were created as modern governments felt the imperative to govern.
The analogy* can extend to non-deterministic products. Every user, every situation, every set of input conditions results in a slightly different product experience. It is impossible to keep track of the countless individual flows that might get created. Instrument your product and create metrics to log everything that happens, for every user. Ultimately, you will need to rely on averages, medians, and points along a distribution to understand your product as there is no one single view.
Here’s an example of the difficulty this poses in practice. From Casey Newton’s recent coverage about Elon Musk trying to understand why the Twitter algorithm is not prioritizing his tweets:
Absurd as Musk’s antics are, they do highlight a tension familiar to almost anyone who has ever used a social network: why are some posts more popular than others? Why am I seeing this thing, and not that one? Engineers for services like TikTok and Instagram can offer partial, high-level answers to these questions. But ranking algorithms make predictions based on hundreds or thousands of signals, and deliver posts to millions of users, making it almost impossible for anyone to say with any degree of accuracy who sees what.
With earlier generations of machine learning — techniques using regression, for example — it would be possible to develop intuition on why the model behaved a certain way, and hence explain outcomes. With techniques like deep learning, ML became a complete black box. It is impossible to know why it does what it does.
(* I must acknowledge that Seeing Like a State is about all the ways centralized planning from governments has failed, but that doesn’t denigrate efforts to gain legibility into a large system comprised of diverse components.)
4. Catch edge cases
The other side of the coin of ‘seeing like a state’ is to pay attention to some individual experiences. After all, your customer isn’t a statistical average of others, but real people or businesses and their experiences are what matter. It becomes important to find and pay attention to the edge cases, wherever they happen, and address them.
You’ve all seen the recent crazy responses by the Bing chatbot Sydney going viral, but here is a good reminder:
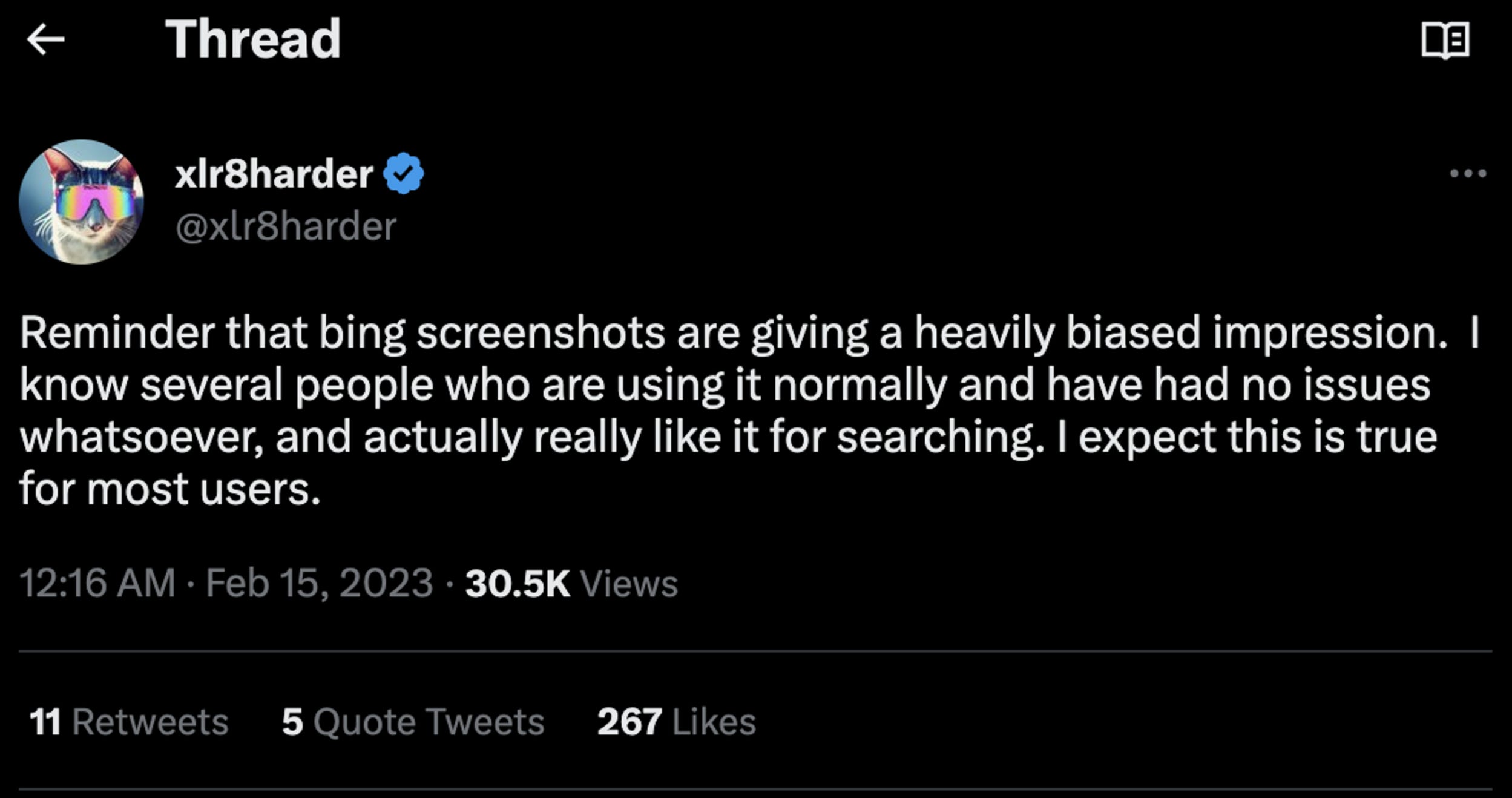
The Twitter algorithm too would be the subject of great ire from a small minority of users. It worked mostly fine for everyone else. The important part is to find these edge cases — the small number of users that encounter your product in an outlier state, and address them. Not only to fix the user experience in those cases, but also because these outlier examples are going to shape the narrative and perception of your product (remember the “pants that followed you on the internet”?).
5. Get ahead of user confusion
People will find non-deterministic products erratic, like in the tweet above about ChatGPT returning different responses, or in the excerpt from Casey Newton’s article. When this happens, they do one of two things: (a) blame themselves for not knowing how to use the product, call it too complicated for them to learn, and quit, or (b) assume something is broken and decide they can’t trust something they can’t understand.
To make matters worse, a machine learning model doesn’t always get the answer right. It learns from its mistakes and improves, but there is nothing quite as maddening as someone who is unpredictable, refuses to explain their process, and got it wrong that one time!
The best way to reduce the dissonance between a blackbox model and how it manifests into a user experience is to:
-
Tell the user what to expect, and
-
Give them some semblance of control and options they can choose from.
(1) is important — there is a significant step change in the experience between deterministic and non-deterministic products. In the … ahem … future, all products will be “non deterministic”; we are in the midst of this shift but until it becomes commonplace, user education will be a key component of the experience. Better onboarding / FTUE / tutorials go a long way to educate users on what to expect and how to deal with unexpected outcomes.
Not doing (2) is a common mistake ML maximalists make. Yes, the dream is to make every product be completely hands-off-the-wheel-self-driving, but don’t start there. If possible, give your users knobs and levers to tweak their experience, or multiple options where they can decide which fits them best. Google Maps gives you multiple routes you can choose from. Twitter lets you switch between the algorithmic feed and the non-algorithmic one. Chat GPT retains context of previous prompts and answers so you can ask follow up questions, revise things, make suggestions.
From how-to-act to how-to-think
That Slack notification flowchart was a set of instructions on how the system should act in every situation. If that system were to be re-done in a non-deterministic manner, the way to approach it is as if you were teaching someone how to think.
Here is one possible way the flowchart might look:
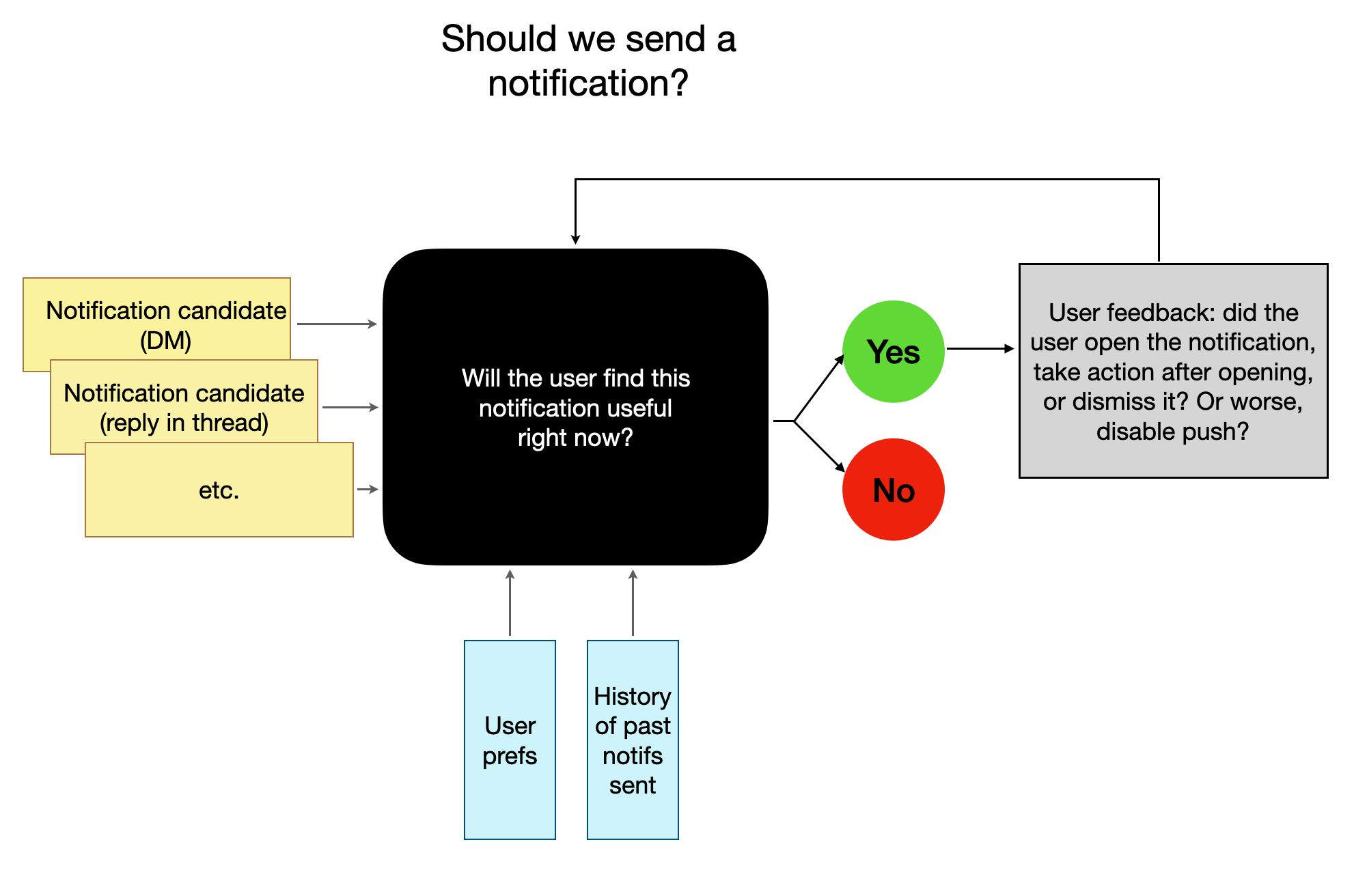
This, of course, is very simplistic. The main point of this illustration is how much of the logic that had to be determined ahead of time moves into a ‘blackbox’ ML model that is constantly learning and improving. Every interesting piece of content simply becomes a “candidate” for a push notification that the model can act on. The heavy lifting now needs to be done on:
Reducing dissonance from the non-deterministic experience for the user, and
Recognizing that the model has needs — feedback loops, user preferences, external context, bootstrapping, etc. — and designing the product to maximizing these inputs to the model.
It is usually hard to simply squeeze machine learning (non-determinism) into an existing deterministic product. Converting it into a non-deterministic product needs many product assumptions and user expectations to be fundamentally reset. But it unlocks much more capabilities as a result.
In our example of Slack notifications, everyone part of a large and active Slack organization suffers from notification fatigue. There is not only a problem of too many notifications (every action you take in the app results in the possibility of multiple notifications coming back to you!), there is also a problem of you missing out on interesting conversations in other parts of Slack simply because they didn’t qualify for the various deterministic rules to trigger a notification. A non-deterministic product would be able to solve both.
We’re only scratching the surface of non-deterministic products. This current wave of generative AI is going to make many more types of products non-deterministic, and likely result in entirely new kinds of products not possible earlier. The gap between what we are accustomed to and expect of our tools and the capabilities of technology products will only widen, and need to be bridged.